母集団から抜き取った標本から得られた値は、母集団の特性値とはズレが生じます。
日本人の調査で、1億2000万人の母集団から、600人を選んで調査をしたら、真の値である1億2000万人の調査結果と、実際に調査した標本の600人の調査結果は、同じになることはありえず、差が出てくるのが普通です。
たとえば、1億2000万人の平均身長と、600人の平均身長にはズレ、誤差が生じます。
※この差、ズレのことを標本誤差と言います。ここでは誤差と書いていきます。
標本のなかのデータ数(標本サイズといいます)を多くすれば、誤差は減っていくだろうと考えられますよね。
上記した日本人の調査であれば、600人よりも1000人、1000人よりも2000人と、増やしていけば、誤差は減っていきます。
しかし、調査する対象人数と誤差の減少の関係には、調査人数を増やすほど、誤差は減りにくくなっていくという性質があります。
この記事では、視聴率を例にあげて、標本サイズを大きくすると、誤差がどのように小さくなっていくか書きました。
データ個数が\(n\)増えると、誤差は\(\frac{1}{\sqrt{n}}\)へと小さくなる
調査をするときには、標本抽出したデータ数が少ないほど誤差は大きくなり、データ数が多いほど誤差は小さくなるのが原則です。
テレビの視聴率調査のことを考えてみます。
視聴率は、日本全国の家庭の全てを調べるのでなく、一部の家庭でどんな番組が見られているのかを調査し、その数値から全国の家庭の視聴率を推定しています。
当然ながら、標本の調査結果の視聴率と実際の日本全国の視聴率には誤差が発生します。
標本の視聴率が、日本全国の視聴率から、どのくらいズレている可能性があるのかは、確率的に示すことができます。それは、標準誤差によって示されます。
標準誤差とは、標本の比率の標準偏差です。
600世帯を対象にある番組の視聴率を調べたら10%でした。でも別で600世帯を対象に同じ番組の視聴率を調べたら12%でした。といった具合で、標本の比率は測定するごとに、ばらつきがあるでしょう。この標本の比率のばらつき度合いを示す標準偏差が、標準誤差と呼ばれます。
標準誤差がわかれば、母集団である日本全体の視聴率から、600世帯の視聴率がどのくらいズレているの可能性があるかわかります。
「日本全国の視聴率から、○○%の確率で、○○から○○の範囲に、標本の視聴率が収まっているだろう」といった具合です。
この「○○%の確率で」のことを信頼係数といい、「○○から○○の範囲」のことを信頼区間と呼び、信頼係数が95%であれば、「視聴率の95%の信頼区間は、…」といった言い方をします。
で、調査結果から得られた視聴率の95%の信頼区間は、
標本の比率\(±1.96\times\sqrt{(p\times(1-p)/ n)}\)
で計算することができます。
例えば、600世帯の調査を行って、ある番組の視聴率が20%という結果が得られたとしたら、
$$1.96\times\sqrt{(0.2\times(1-0.2)/600)}$$
ですから、誤差は0.032 になります。つまり、日本全国の視聴率は、95%の確率で標本の視聴率20%から±3.2%の範囲に収まるだろうと推定できます。
95%は高い確率です。ズレのことを誤差と呼ぶとしたら、誤差は高い確率で、±3.2%程度になるだろう、と予測できます。
標本サイズを大きくする、つまりサンプルのなかのデータ個数n の数を増やしていくと、式を見てもわかるように、誤差は\(\frac{1}{\sqrt{n}}\)に小さくなります。
データ個数n を2倍に増やしたら、誤差範囲もその分減少する、つまり\(\frac{1}{2}\)になるのかなと思いきや、そうではなくて\(\frac{1}{\sqrt{2}}\)になって減少するのです。データ数n を3倍に増やしたら、誤差範囲は\(\frac{1}{\sqrt{3}}\)になって減少します。
n=2になれば、誤差は\(\frac{1}{\sqrt{1.4}}\)に
n=4になれば、誤差は\(\frac{1}{\sqrt{2}}\)に
n=100になれば、誤差は\(\frac{1}{\sqrt{10}}\)に
なります。
誤差の減り具合を表とグラフで見てみる
標本比率が20%の場合で話を進めていきます。標本比率20%の95%信頼区間を表にしました。
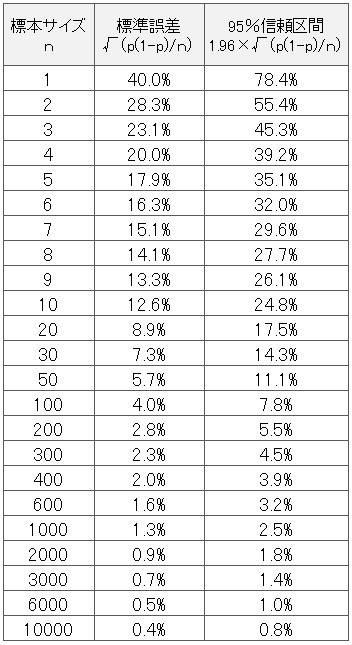
標本のデータ数n が増えていくほど、誤差の減り具合が減っていきます。たとえば、 95%信頼区間の誤差は、標本のデータ数n=2 のときには55.4%もありますが、n=30になると14.3%にぐっと減少します。
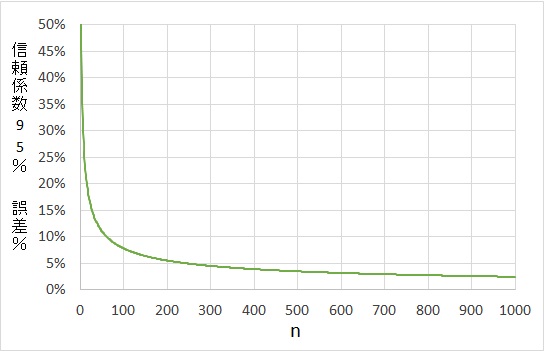
さらにn=100に増やすと、7.8%に減少します。そこからさらに増やして、n=400~600にかけては、誤差の減少が緩くなってきていますね。グラフを見るとよくわかります。
n=1~1,000までのグラフです。
さらにnを1~10,000まで表示するとこのようになります。
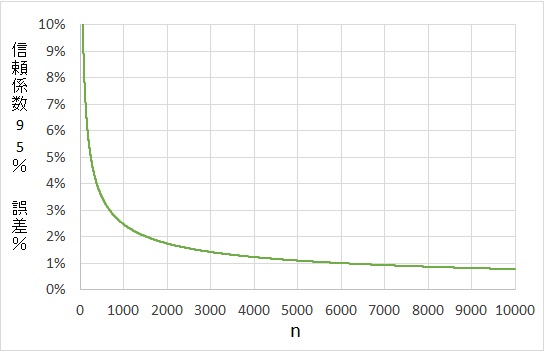
nを10から100に増やすと、誤差は24.8%から7.8%になりますから、14%分も減少したことになります。
しかし、nを3000から6000にした場合、n=3000で誤差1.4%、n=6000で誤差1.0%であり、nが3000増えたのにも関わらず、誤差の減り具合はたったの0.4%です。
ところで、統計調査での充分なデータ数n は3000などと言われています。
n=100の調査では、誤差が大きく、n=600くらいにすれば誤差が許容できる範囲に落ち着いてはきますが、まだある程度の誤差があるといえばあります。
しっかりとした統計調査では、さらに誤差が少なくなるまで標本のデータ数n を増やし、これ以上増やしても、効果がほとんど出なくなってくるn=3000を目安にしているのでしょう。
データは必要最小限の量を集める
ある標本のデータ数nをある数から、nを2倍にすると、誤差は\(\frac{1}{\sqrt{2}}\)になります。 nを増やしてa倍の数にすると、誤差は\(\frac{1}{\sqrt{a}}\)倍となるのです。
調査・分析をするときに、2倍の量のデータを集めれば、母集団と標本のズレも2倍くらい無くなるだろうと考えてしまうかもしれませんが、それは間違いです。
上記のグラフで見たようにデータをとればとるほど、誤差は無くなり精度は高まるには高まるのですが、 その精度は高まりづらくなっていくのです。
やみくもにたくさんデータを集めればいいわけではないことがわかります。
600人で誤差は3.2%でした。それを2倍の1200人に増やしてみましょう。1200人の場合、誤差は2.3%になります。
誤差が\(\frac{1}{\sqrt{2}}\)に小さくなっていることがわかります。
\(3.2%\times\frac{1}{1.4}=2.3%\)
です。
600人から追加で5400人に頑張って調査、標本数を6000にすると、誤差が3.2%から1.0%へ、2.2%分減少します。
そこから、同じくらい頑張って5400人に追加調査をしました。合計11400人の調査をするとどうなるか。6000人調査して誤差が1.0%だったところから、11400人では誤差が0.7%に減少します。
同じように5400人追加して調査を実施したのですが、0.3%しか減少しませんでした。
このように、標本のデータ数を増やしていくほど、誤差が小さくなる効果が減少していきます。
とにかくデータの数を増やせば正確な調査結果が得られるのだ!と増やしてばかりいると、 労力の割に、誤差は小さくならず、疲れてしまうだけです。
ほどよいところで、調査、データ収集を切り上げるようにします。必要以上にデータを集めないことです。 ほどよいところとは、どこなのか?
データを集めて分析するのは、いうまでもなく分析自体が目的ではありません。分析の結果を見て、何かしらの判断や意思決定をしてアクションを起こすために、データを集めて分析するのです。
だとすると、調査結果の精度はやみくもに求める必要はなく、正しい判断をするのに必要なデータの精度を知り、そのデータの精度を出すのに必要な調査量を決め、その分だけ調査を実施すればいいのです。